Note for Memory Networks
MEMORY NETWORKS
Overall
这篇论文借助神经图灵机的思路,把NTM的读写机制转成具体的四个步骤,这四个步骤在文中的表述如下:



I步骤将输入的信息转化为隐层的表示(feature representation),而G步骤则是用来更新(写)memory(此处的memory可以是对应的某个句子的向量,即I(x)),而O步骤则是为了获取(读)memory,并结合上一层的输出,输入到该层网络,得到新的feature,最后R步骤则是把feature映射为final response。
MEMNN
假设任务是输入多个句子,然后输出是某个词(该词包含在整个vocabrary里)
- I步骤是常规步骤
- G步骤需要考虑记录(可以用I(x)进行hash检索记忆块,得到$m_{I(x)}$,比较简单的存储memory的方式为$m_{I(x)}=I(x)$),当记录内容较大时(require huge memory),可以考虑存储一些group information(memory slot,像话题聚类的每个话题代表一个slot,里面包含多个同主题句子;或者每个词对应一个slot,里面包含有改词的所有句子),memory可以有forget机制(可以用新的memory覆盖掉很旧的或者长时间没有响应的)
- O步骤需要从memory里取信息(此处是句子),假设取k=2个memory,可以通过如下方式取得:
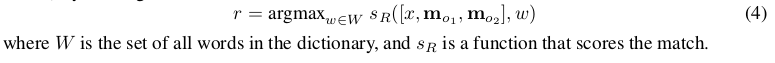
- 最终的输出可以通过如下方式得到:

scoring function可以如下:
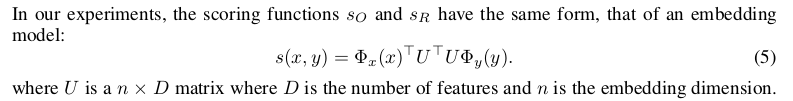
对于训练的loss function,可以是考虑三个阶段的hinge loss相加
- 选取第一个memory的时候(选对的和选错的做差)
- 选取第二个memory的时候(选对的和选错的做差)
- 选择最终的输出词的时候(选对的和选错的做差)
最终形式可以如下:

学习的参数为$s_O$和$s_R$函数里的$U_O$和$U_R$
End-To-End Memory Networks
上一篇的memory networks并不适合用bp训练,并且不是端到端的(看损失函数就可以判断需要考虑中间过程的输出),训练起来不方便。本文提出了一种端到端的思路,弱化了这种监督。本文提出的memory机制,类似基于全局训练集的一种attention机制,能够提供大型的外部memory来(多次,即多层,多个hop的时候)查询,与RNN的短期记忆相互补充。这种端到端的方式使得模型的可扩展性更强。
Architecture
本文以QA为例子,输入多个passage,一个question,输出一个answer(假设为一个词)。

single layer
文章的输入需要考虑将每个passage/sentence转成bag of words(维度为V)的形式,之后通过A矩阵映射为memory,通过与question向量u内积得到一组attention,作用于通过B矩阵映射的passage的输出,最终得到一个向量o,再和u相加通过一个矩阵W变换,与一个softmax得到维度为V的概率输出。
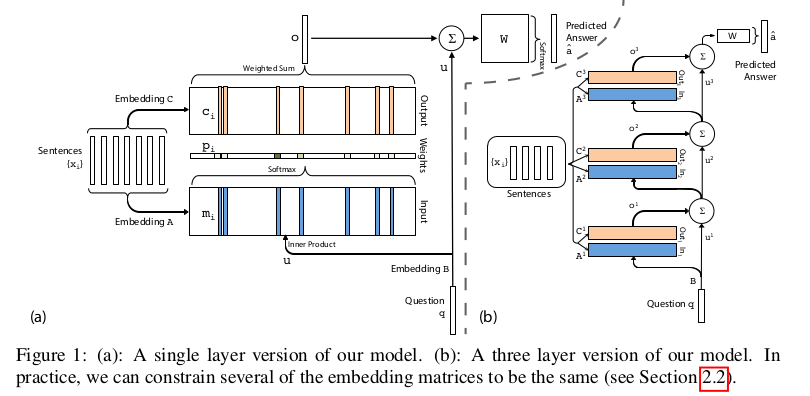
multiple layer
是之前单层的扩展,有几层就有几个hop。文中考虑两种参数共享方式:
- Adjacent:相邻两个矩阵共享参数,比如上图的$A^{i+1}=C^i$与$W^T=C^K$与$B=A^1$
- Layer-wise:每层参数共享,比如上图的$A^1=A^2=…=A^{K}$与$C^1=C^2=…=C^{K}$
Experiment
作者拿原版的MemNN,MemNN-WSH和LSTM作为baseline,分别进行了QA和language modeling两个应用场景的实验。还对比了不同embedding方式的效果。
Conclusion
相较于传统RNN,建立了更长的memory依赖,训练end-to-end,不需要太多的人为监督,在不同任务之间迁移性好。而且多步计算的方法也提高了精度。但是相较于传统强监督的memory network,效果还是差了点。而且memory的规模太大,查询代价变高了。end-to-end模型也难以回溯。