Note for “Neural Text Generation: A Practical Guide”
Introduction
主要讲NTG的training和decoding部分,并给出一些实践的经验。
Background
常用模型
- CNN + Attention
- RNN + Attention
- CNN + RNN + Attention
Training overview
training loss:
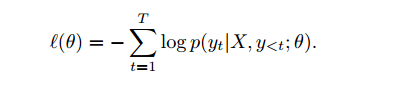
Decoding overview
如何根据模型得到结果比较好的解。可以使用greedy decoding,可以高效的找到较优解,而不保证找到最优解(非全局最优)。
常用的greedy decoding比如有beam search。假设beam search的beam size为k,则beam search的大致流程如下:
- 初始化假设空间H={[<sos>]},表示target部分的开始
- 对于每个timestep:
- 对于假设空间的每一个假设$H_i$:
- 对于当前位置的每一个词与假设$H_i$
- 我们计算其得分(可以是单纯的对数概率相加,也可以是用已经训练好的语言模型打分,或两者按一定比例加权)
- 如果当前的假设$H_i$的结尾为<eos>,则将该假设存到$H_{final}$
- 从大约n*k条路径中选出k条目前得分最高的路径,并更新到$H_{(i+1)}$
- 最终得分为$H^*=argmax_{H_{final}}s(H)$
- 对于假设空间的每一个假设$H_i$:
较小的beam size效果较好,再大效果可能会变差。
Attention
算是encoder-decoder的标配了,可以直接连接target与source。self-attention可以做成是当前词之前的已经被解码出来的decoder的隐藏层输出的加权。
Evaluation
Perplexity不能较好的反映模型效果。n-gram的metrics如BLEU和ROUGE也只是粗略的评价,并不会考虑到语言的流畅性和连贯性。尽管如此,这些指标还是可以用来评价model development(模型好坏是一个相对的指标)。
Preprocessing
数据预处理的工作,可以考虑分词(character level or subword level)、字符编码等问题。
Training
一些启发式的超参设置与优化技巧
- 按句子长度进行排序,然后取batch,可节省计算
- 如果数据量较小,可以加强regularization(如token dropout和l2正则)
- 模拟退火来调节learning rate
- loss和performance并不一定对齐,所以最好周期性的保存模型并测试模型的performance(可用于之后融合多个performance相近的结果)
- 考虑emsembling,可以是多个不同模型的emsembling,也可以是同一个模型的多个checkpoint的emsembling
Decoding
Diagnostics
- scoring function可以表名一个假设有多“合理”,可以通过比较predict target和true target的得分比值ratio来确定。如果ratio过小,说明beam size太小,没有涵盖到true target,如果ratio太大,则说明scoring function不合理
- 在大语料上训练的语言模型,用的语料domain可能和target的语料的domain不相似,即需要适当选择语言模型在NTG任务中的打分权重
Common issues
OOV words
可以直接对输出词类别数进行truncate
Decoded output short, truncated or ignore portions of input
解决short output
- length penalty and length bonus
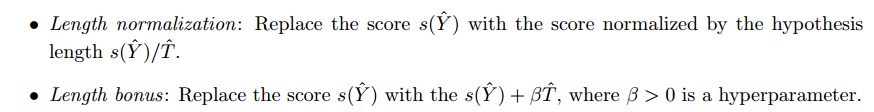
- coverage penalty

约束target length与source length接近

Decoded output repeats
可以考虑加一个重复词的惩罚
Lack of diversity
多样性可以通过以下方法:
-
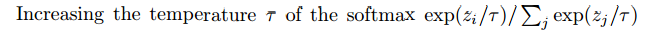
-
在beam search过程中加入一个penalty
-
最大化target与source的互信息
References
Neural Text Generation: A Practical Guide