蚂蚁金服-金融智能NLP服务Rank2解决方案
问题分析
给定两个短文本,通过算法计算两个问题的相似度,进而判定两个问题是否在语义上一致。数据集的大小如下。一般在检索中,我们更多的是去做词匹配(word match)相关的工作,而在这个任务中,我们的目的则是去做语义匹配(paraphrasing)。
该任务的指标为F1 score。
| 比赛阶段 | 训练集 | 测试集 |
|---|---|---|
| 初赛 | 10W+ | 1W |
| 复赛 | 49W+ | 1W |
特征提取
通常在做这类NLP问题的时候,会尝试如下一些特征。不过这些特征在此任务中并没有发挥比较好的作用。
- 字数差
- 词数差
- 重复词统计、比例
- 停用词统计、比例
- 编辑距离
- tfidf向量(的比较)
- 降维的tfidf向量(的比较)
- LDA向量(的比较)
- 句子embedding向量(的比较)
- 数据集的图特征(比如样本[q1, q2]可以看成两个节点和一条无向边)
预训练
在该任务中,我们尝试了两种预训练字/词向量。
- Word2vec:基于gensim训练的词向量,语聊为训练集;
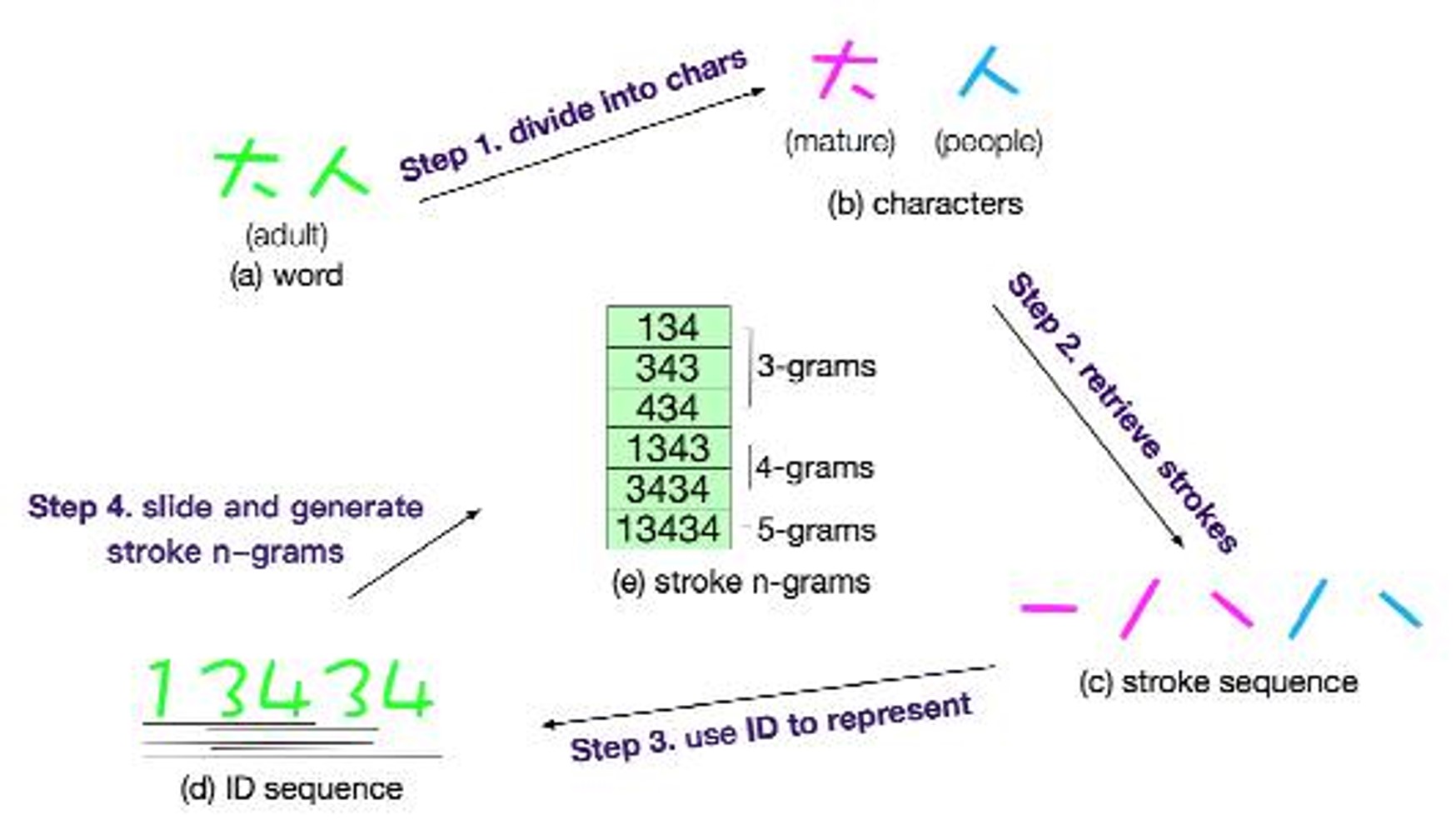
- cw2vec:基于fasttext训练的词向量,语聊为训练集。该方法是讲每个字/词拆解成笔画顺序后进行训练,与英文单词由字母序列构成的思路类似,可作subword的训练。
该任务中,我们同时也考虑词序列、字序列、由字构成的词序列三种模型输入方式。比如: 原句:怎么更改花呗手机号码 字序列:[怎 么 更 改 花 呗 手 机 号 码] 词序列:[怎么 更改 花呗 手机 号码] 字表示的词序列:[[怎 么] [更 改] [花 呗] [手 机] [号 码]]
模型构建
在该任务中,我们使用了5种模型,其中我们设计的simpleNN单模型效果最佳。
- 基于RNN的向量距离比较模型simpleNN(最优模型)
- CNN+RNN模型RCNN
- RNN+Attention对齐的GRUNN
- BIMPM
- ESIM
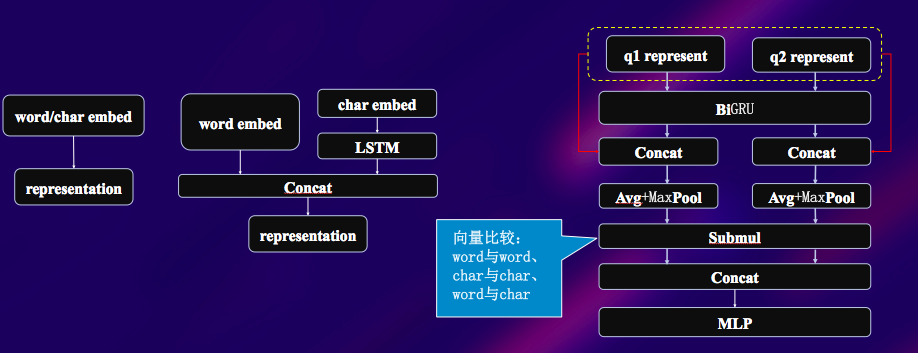
simpleNN
- 三种输入源(词序列+由字构成的词序列、字序列、词序列+字序列)
- 两种不同来源的embedding(word2vec以及cw2vec)
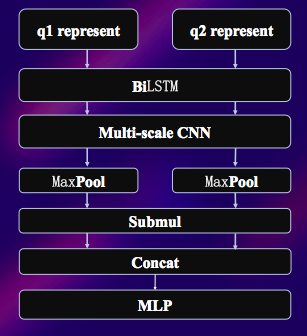
RCNN
- Bi-LSTM进行上下文编码
- 得到上下文编码序列后,利用Multi-scale的CNN进行ngram信息抓取
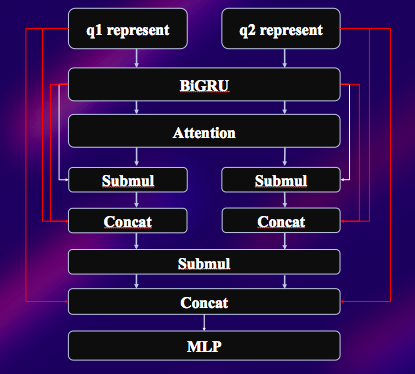
GRUNN
- 考虑浅层信息
- 考虑语义编码信息
- 考虑attention信息
- 考虑语义编码与attention的比较信息
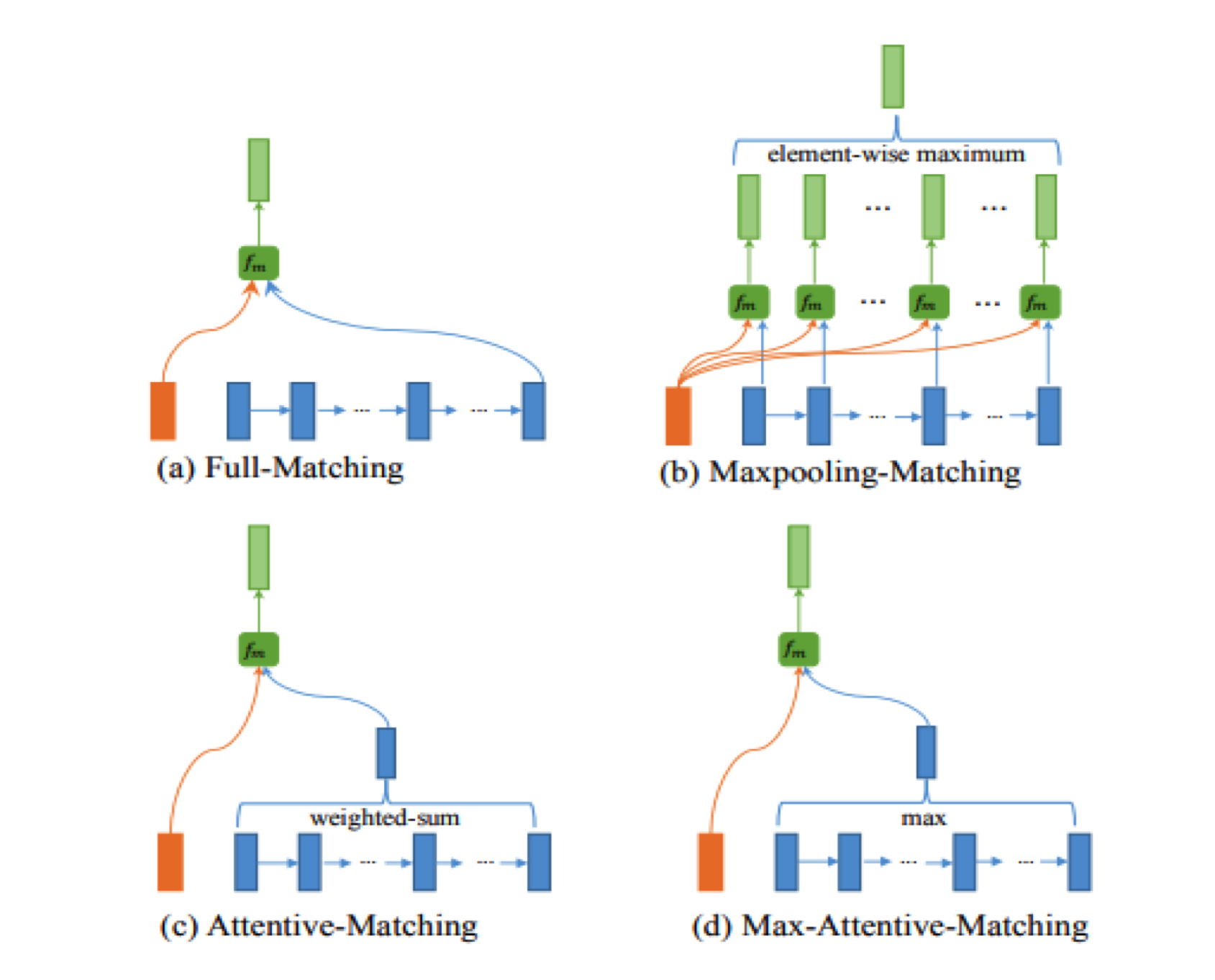
BiMPM
- 全称Bilateral Multi-Perspective Matching
- 基于字/词粒度的比较
- Context layer 使用LSTM+Highway完成encode工作
- Matching layr 基于Attention原理产生8对matching向量

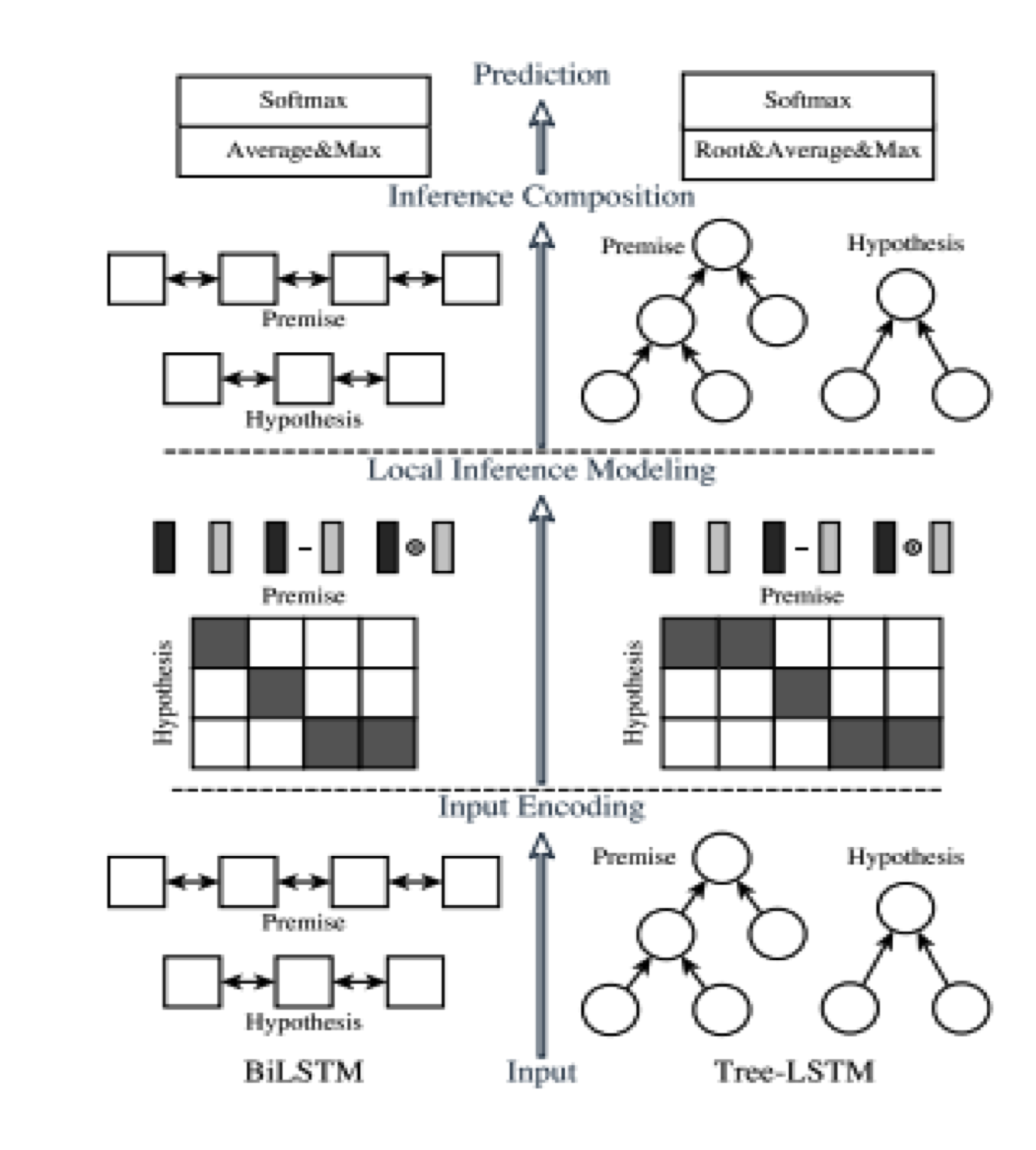
ESIM
- 全称Enhanced Sequential Inference Model
- 该模型比一般语言模型特有的Inference机制,利用两文本互为上下文推理
- 考虑原始词与attention表示的词的比较
- 选用了BiLSTM编码方式
- 采用退火训练方式防止过拟合(学习率随着迭代次数增多而下降)
Finetune
- gensim/fasttext训练词向量;
- 模型使用non_trainable词向量进行训练;
- 将除了embedding的layer所有梯度进行clip与scale,同时用低学习率finetune词向量层。
模型融合
- 采用等权重加权的方式融合模型预测的prob;
- 训练样本足够多,使用stacking + lr模型敲定融合参数,并泛化防止过拟合;
- 模型训练时间不充分,需要人工监控每个模型输出的prob分布,通过等权加权的mean与std的方式分配权重,使得分配的权重加权后的mean和std与等权加权的尽量一致。
模型优缺点
优点
- 词向量预训练考虑中文特殊性:考虑中文词,采用了cw2vec;
- 模型大量使用shortcut设计防止过拟合:引入浅层语义,防止模型深度过深造成的过拟合
- 控制模型数量的情况下保证异构性足够大:让模型尝试从不同角度去看数据
- 融合方案针对评价指标设计,鲁棒性优秀:按照指标进行monitor与early stop
缺点
- 文本预处理可以更加完善,比如错别字修正以及简繁字转换
- BiMPM及ESIM过拟合较严重,还有改进空间
- 对PAI平台的不熟悉,还有很多组件和模型未进行探索
可以尝试的提升点
- 使用更大的中文语料训练词向量
- 利用拼音的embedding辅助纠正错别字与繁体转简体
- query的词法(词性与实体等)分析
- 尝试更多模型
参考文献
- Paul Neculoiu, Maarten Versteegh, Mihai Rotaru: Learning Text Similarity with Siamese Recurrent Networks. Rep4NLP@ACL 2016: 148-157
- B. Wang, L. Wang, et.al. Joint Learning of Siamese CNNs and Temporally Constrained Metrics for Tracklet Association
- Qian Chen, Xiaodan Zhu, Zhen-Hua Ling, Si Wei, Hui Jiang, Diana Inkpen: Enhanced LSTM for Natural Language Inference. ACL (1) 2017
- Sumit Chopra, Raia Hadsell, Yann LeCun: Learning a Similarity Metric Discriminatively, with Application to Face Verification. CVPR (1) 2005
- Mohammad Norouzi, David J. Fleet, Ruslan Salakhutdinov: Hamming Distance Metric Learning. NIPS 2012
- Zhiguo Wang, Wael Hamza, Radu Florian: Bilateral Multi-Perspective Matching for Natural Language Sentences. IJCAI 2017: 4144-4150