Previous
自然语言处理——语言模型
自然语言处理——词法分析与词性标注
自然语言处理——语法分析
自然语言处理——句法分析
任务
识别句子的句法结构
分类
短语结构分析(完全句法分析、局部句法分析)、依存句法分析
目标
正确性、鲁棒性
问题
- 句子歧义性(结构歧义):一个句子可能可以得到多个不同的句法解析树
- 长句分析问题:长句子由各个短句构成,如果一个短句的句法解析出问题,会影响整个句子的句法解析
- 可以考虑标点符号的作用
- 考虑层次化长句结构来分析
分析方法
基于CFG规则的分析方法
- 线树分析法(Bottom-up、Top-down、两者结合)
- 优点:算法简单开发周期短
- 缺点:(1)时间复杂度高(O(K*n^3));(2)分析质量依赖于给出的规则;(3)难以区分句子歧义
- CYK算法
- 优点:算法简单清晰、效率高
- 缺点:(1)需要对文法进行规范化;(二叉树结构)(2)无法解决句子歧义结构
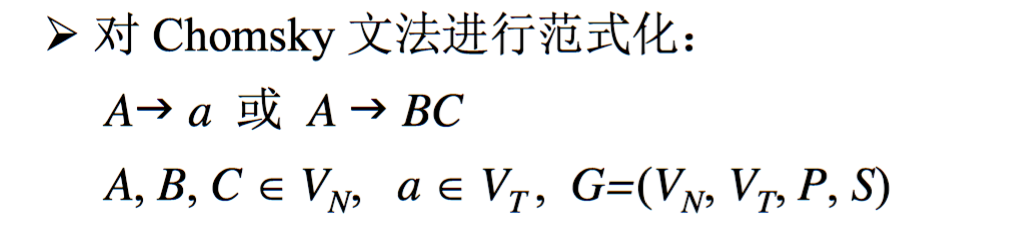
- Earley算法
- LR算法
基于PCFG规则的分析方法(就是在CFG的基础加,给定每个文法规则一个概率值)
- 概率假设:
- 位置不变性:子树的概率和在句子中的位置无关;
- 上下文无关性:子树的概率和子树之外的词无关;
- 祖先无关性:子树的概率和产生该子树的祖先结点无关
- 优点:利用概率减少分析过程的搜索空间、利用概率对概率较小的子树剪枝加快效率、可以定量的比较两个语法的性能
- 缺点:无法统计共现信息(词和词、短语和短语)
- 评价指标:语法的覆盖性、树相似性、模型的熵(困惑度)、PARSEVAL评测方法(标记准确率、标记召回率、F1、交叉括号数)等等
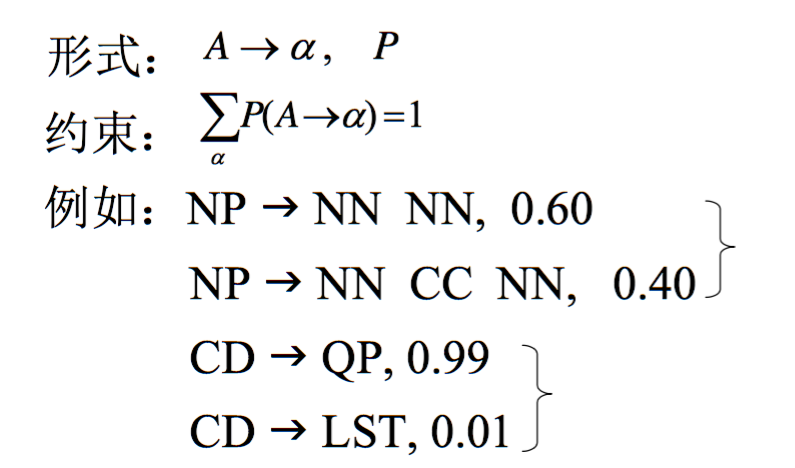
类似HMM,运用PCFG也有这样的三个问题:

第一个问题:使用内向算法,即自底向上(也可以使用外向算法,即自上到下)




外向算法

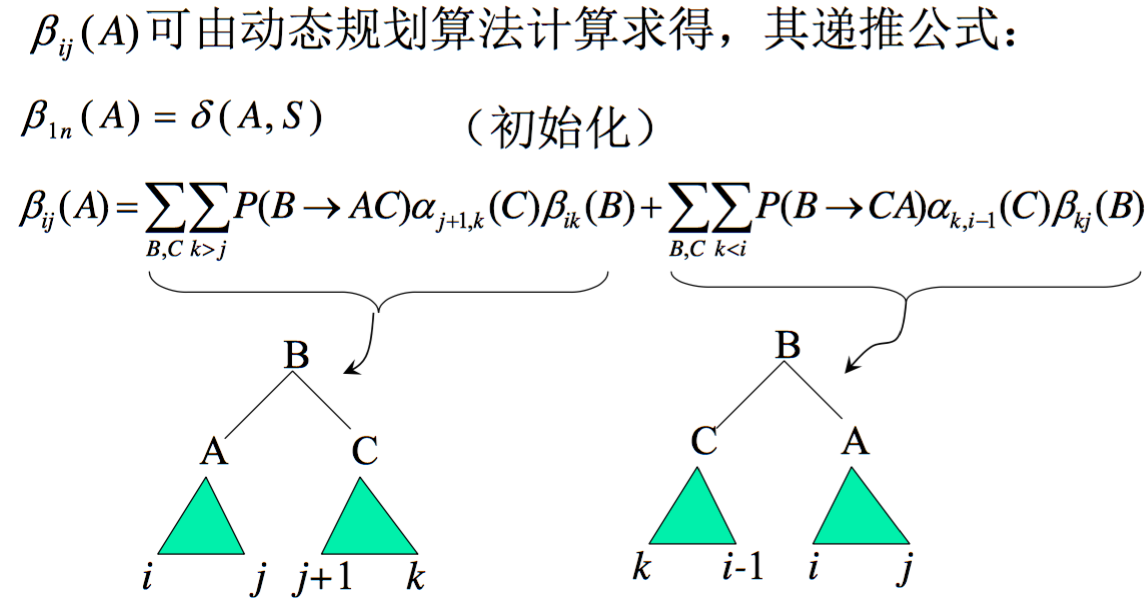
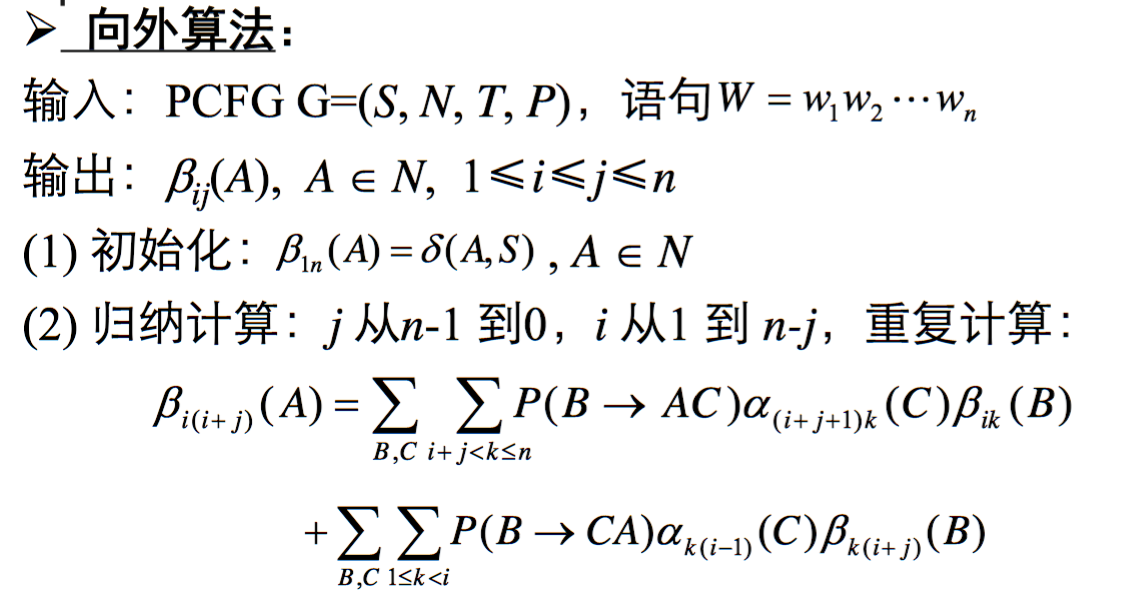
第二个问题:使用维特比算法


第三个:使用向内-向外算法学习模型(即EM算法)
- 有充足的标注语料(即句法分析树):直接进行参数估计(统计)
- 没有充足的标注语料:使用EM算法迭代收敛



注:
开塔兰数:英语中的结构歧义随着介词短语组合个数的增加而不断加深,这个数叫做开塔兰数