APPLYING DEEP LEARNING TO ANSWER SELECTION:A STUDY AND AN OPEN TASK浅见
零、主要目的
建立一个保险领域的QA系统,即客户给出一个问题,在知识库中寻找与之最为匹配的答案。
一、 注意点
原文1
a CNN leverages three important ideas that can help improve a machine learning system: sparse interaction, parameter sharing and equivariant representation. Sparse interaction contrasts with traditional neural networks where each output is interactive with each input. In a CNN, the filter size (or kernel size) is usually much smaller than the input size. As a result , the output is only interactive with a narrow window of the input. Parameter sharing refers to reusing the filter parameters in the convolution operations, while the element in the weight matrix of traditional neural network will be used only once to calculate the output. Equivariant representation is related to the idea of k-MaxPooling which is usually combined with a CNN.
大致内容:
CNN利用了三个重要的思路,能够帮助改善机器学习系统:稀疏交互(sparse interaction)、参数共享(parameter sharing)和等变表示(equivariant representation)。稀疏交互和传统神经网络的每个输出都与输入进行交互(全连接)形成对比。在CNN中,过滤器尺寸(核大小)通常比输入大小要小很多。因此,CNN网络内部的输出仅仅和一个输入的窄窗交互。而参数共享是指在一次卷积过程中重复使用过滤器的参数(即一个通道channel只使用一个filter),而传统神经网络中的权重矩阵元素只在计算输出的时候被使用一次。等变表示类似于经常与CNN组合在一起的k最大池化的思想(即在一个池中选择k个最大值)。
原文2
During training, for each training question Q there is a positive answer A+(the ground truth). A training instance is constructed by pairing this A+ with a negative answer A−(a wrong answer) sampled from the whole answer space.
大致内容:
在训练的时候,对每个训练问题Q,总会有一个正答案A+(事实)。一个训练实例是通过从整个答案空间里抽取的这个正答案A+和一个负答案A-(错误答案)形成对。
三、细节
-
两个baseline:BOW and IR model
-
该论文损失函数使用的是Hinge Loss:$L=max\{0, m-cos(V_Q,V_{A+})+cos(V_Q,V_{A-})\}$ ,其中$m$为margin。
框架(详细说明框架2)
框架1:
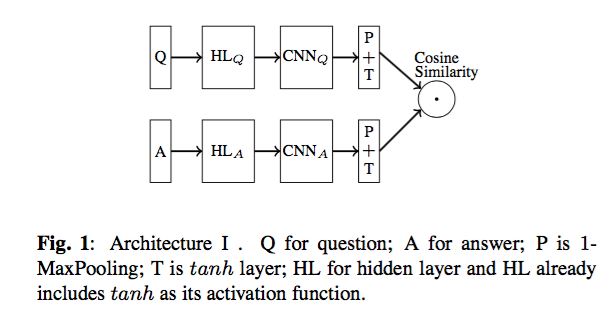
Q语句和A语句分别处理,各自独立使用HL层、CNN层、P层和T层。
框架2:
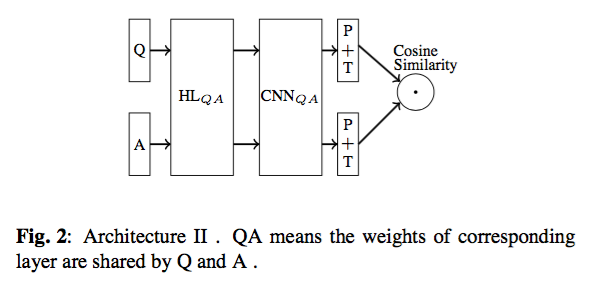
- 输入Q和A为[batch_size, sequence_length, embed_size]
- HL(Hidden Layer)使用tanh函数,输出为[batch_size, sequence_length, hidden_size]
- 之后经过CNN层,为带多个filter的单卷积层,输出为[batch_size, sequence_size-filter_size+1, 1, channels],经过P(1-max-pooling)后为[batch_size, 1, 1, channels]
- 如果有n个不同类型的filter,则最后输出为[batch_size, 1, 1, channels*n]
- 再经过reshape后,可以转为[batch_size, channels*n],之后再计算batch里每个样本的余弦相似度,最后输出为[batch_size]
框架3:
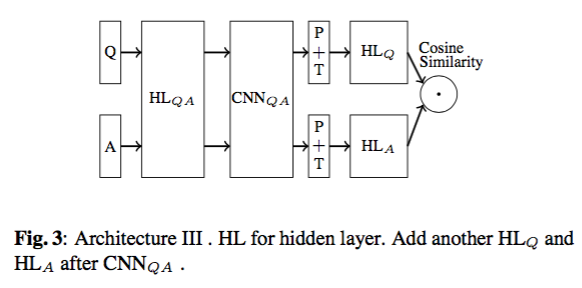
框架4:
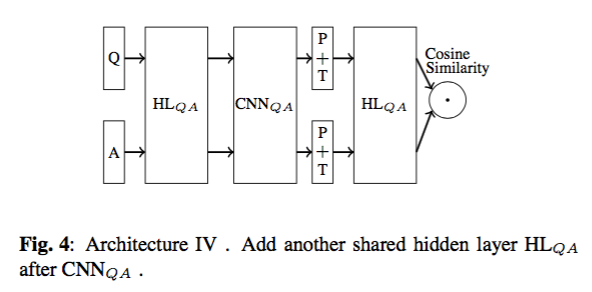
框架5:
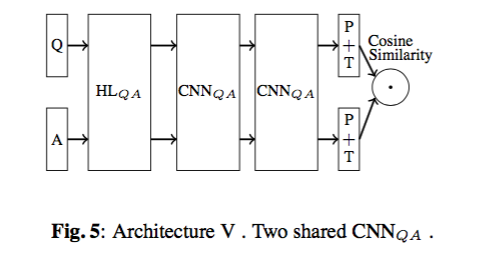
框架6:
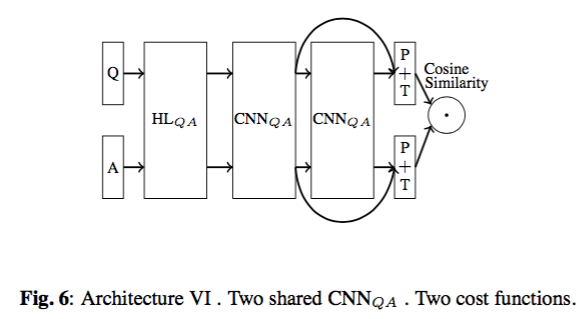
四、实现
每个框架的实现都差不多,论文里也都做了比较,如下:

可以看到框架2的效果最好。按照框架2复现一下代码,结构大致按照图中显示的和论文中提及的部分来做。有些论文没有详述的,或者论文给定参数和实际实验效果不符的,都需要自定义。
数据说明
- test1 10000个测试样例,共20个问题,每个问题500个,对应1到2个正确答案,499到498个错误答案。相当于从一个size=500的pool里选出正确答案。
- train 18540个训练样本。
- vectors.nobin 22353个预训练的词向量,此实验中没有用。
训练和测试数据是原论文集给出的一小部分,如果需要完整的数据,可以到参考里的github网站下载。
框架2实现
使用python和Tensorflow实现。具体内容已添加到代码注释里。
QACNN网络 qacnn.py
Model只是一个抽象类。
# -*- encoding:utf-8 -*-
import tensorflow as tf
import numpy as np
from model import Model
# QA的CNN网络,自底向上为:
# word embedding
# tanh隐藏层
# convolution+tanh
# 1-max-pooling+tanh(Q和A分开)
# 计算cosine
class QACNN(Model):
def __init__(self, config, sess):
self.config = config
self.sess = sess
# 输入
self.add_placeholders()
# [batch_size, sequence_size, embed_size]
q_embed, aplus_embed, aminus_embed = self.add_embeddings()
# [batch_size, sequence_size, hidden_size, 1]
self.h_q, self.h_ap, self.h_am = self.add_hl(q_embed, aplus_embed, aminus_embed)
# [batch_size, total_channels]
real_pool_q, real_pool_ap, real_pool_am = self.add_model(self.h_q, self.h_ap, self.h_am)
# [batch_size, 1]
self.q_ap_cosine, self.q_am_cosine = self.calc_cosine(real_pool_q, real_pool_ap, real_pool_am)
# 损失和精确度
self.total_loss, self.loss, self.accu = self.add_loss_op(self.q_ap_cosine, self.q_am_cosine)
# 训练节点
self.train_op = self.add_train_op(self.total_loss)
# 输入
def add_placeholders(self):
# 问题
self.q = tf.placeholder(np.int32,
shape=[self.config.batch_size, self.config.sequence_length],
name='Question')
# 正向回答
self.aplus = tf.placeholder(np.int32,
shape=[self.config.batch_size, self.config.sequence_length],
name='PosAns')
# 负向回答
self.aminus = tf.placeholder(np.int32,
shape=[self.config.batch_size, self.config.sequence_length],
name='NegAns')
# drop_out
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
# word embeddings
def add_embeddings(self):
with tf.variable_scope('embedding'):
embeddings = tf.get_variable('embeddings', shape=[self.config.vocab_size, self.config.embedding_size], initializer=tf.uniform_unit_scaling_initializer())
q_embed = tf.nn.embedding_lookup(embeddings, self.q)
aplus_embed = tf.nn.embedding_lookup(embeddings, self.aplus)
aminus_embed = tf.nn.embedding_lookup(embeddings, self.aminus)
return q_embed, aplus_embed, aminus_embed
# Hidden Layer
def add_hl(self, q_embed, aplus_embed, aminus_embed):
with tf.variable_scope('HL'):
W = tf.get_variable('weights', shape=[self.config.embedding_size, self.config.hidden_size], initializer=tf.uniform_unit_scaling_initializer())
b = tf.get_variable('biases', initializer=tf.constant(0.1, shape=[self.config.hidden_size]))
h_q = tf.reshape(tf.nn.tanh(tf.matmul(tf.reshape(q_embed, [-1, self.config.embedding_size]), W)+b), [self.config.batch_size, self.config.sequence_length, -1])
h_ap = tf.reshape(tf.nn.tanh(tf.matmul(tf.reshape(aplus_embed, [-1, self.config.embedding_size]), W)+b), [self.config.batch_size, self.config.sequence_length, -1])
h_am = tf.reshape(tf.nn.tanh(tf.matmul(tf.reshape(aminus_embed, [-1, self.config.embedding_size]), W)+b), [self.config.batch_size, self.config.sequence_length, -1])
tf.add_to_collection('total_loss', 0.5*self.config.l2_reg_lambda*tf.nn.l2_loss(W))
# print 'h_q[shape]:', tf.shape(h_q)
# print 'h_ap[shape]:', tf.shape(h_ap)
# print 'h_am[shape]:', tf.shape(h_am)
return h_q, h_ap, h_am
# CNN层
def add_model(self, h_q, h_ap, h_am):
pool_q = list()
pool_ap = list()
pool_am = list()
h_q = tf.reshape(h_q, [-1, self.config.sequence_length, self.config.hidden_size, 1])
h_ap = tf.reshape(h_ap, [-1, self.config.sequence_length, self.config.hidden_size, 1])
h_am = tf.reshape(h_am, [-1, self.config.sequence_length, self.config.hidden_size, 1])
for i, filter_size in enumerate(self.config.filter_sizes):
with tf.variable_scope('filter{}'.format(filter_size)):
# filter的W和b
conv1_W = tf.get_variable('W', shape=[filter_size, self.config.hidden_size, 1, self.config.num_filters], initializer=tf.truncated_normal_initializer(.0, .1))
conv1_b = tf.get_variable('conv_b', initializer=tf.constant(0.1, shape=[self.config.num_filters]))
# pooling层的bias,Q和A分开
pool_qb = tf.get_variable('pool_qb', initializer=tf.constant(0.1, shape=[self.config.num_filters]))
pool_ab = tf.get_variable('pool_ab', initializer=tf.constant(0.1, shape=[self.config.num_filters]))
# 卷积
out_q = tf.nn.relu((tf.nn.conv2d(h_q, conv1_W, [1,1,1,1], padding='VALID')+conv1_b))
# 池化
out_q = tf.nn.max_pool(out_q, [1,self.config.sequence_length-filter_size+1,1,1], [1,1,1,1], padding='VALID')
out_q = tf.nn.tanh(out_q+pool_qb)
pool_q.append(out_q)
out_ap = tf.nn.relu((tf.nn.conv2d(h_ap, conv1_W, [1,1,1,1], padding='VALID')+conv1_b))
out_ap = tf.nn.max_pool(out_ap, [1,self.config.sequence_length-filter_size+1,1,1], [1,1,1,1], padding='VALID')
out_ap = tf.nn.tanh(out_ap+pool_ab)
pool_ap.append(out_ap)
out_am = tf.nn.relu((tf.nn.conv2d(h_am, conv1_W, [1,1,1,1], padding='VALID')+conv1_b))
out_am = tf.nn.max_pool(out_am, [1,self.config.sequence_length-filter_size+1,1,1], [1,1,1,1], padding='VALID')
out_am = tf.nn.tanh(out_am+pool_ab)
pool_am.append(out_am)
# 加入正则项
tf.add_to_collection('total_loss', 0.5*self.config.l2_reg_lambda*tf.nn.l2_loss(conv1_W))
total_channels = len(self.config.filter_sizes)*self.config.num_filters
real_pool_q = tf.reshape(tf.concat(3, pool_q), [-1, total_channels])
real_pool_ap = tf.reshape(tf.concat(3, pool_ap), [-1, total_channels])
real_pool_am = tf.reshape(tf.concat(3, pool_am), [-1, total_channels])
# print 'real_pool_q[shape]:', tf.shape(real_pool_q)
# print 'real_pool_ap[shape]:', tf.shape(real_pool_ap)
# print 'real_pool_am[shape]:', tf.shape(real_pool_am)
return real_pool_q, real_pool_ap, real_pool_am
# 计算cosine
def calc_cosine(self, real_pool_q, real_pool_ap, real_pool_am):
len_pool_q = tf.sqrt(tf.reduce_sum(tf.pow(real_pool_q, 2), [1]))
len_pool_ap = tf.sqrt(tf.reduce_sum(tf.pow(real_pool_ap, 2), [1]))
len_pool_am = tf.sqrt(tf.reduce_sum(tf.pow(real_pool_am, 2), [1]))
# print 'len_pool_q[shape]:', tf.shape(len_pool_q)
# print 'len_pool_ap[shape]:', tf.shape(len_pool_ap)
# print 'len_pool_am[shape]:', tf.shape(len_pool_am)
q_ap_cosine = tf.div(tf.reduce_sum(tf.mul(real_pool_q, real_pool_ap), [1]), tf.mul(len_pool_q, len_pool_ap))
q_am_cosine = tf.div(tf.reduce_sum(tf.mul(real_pool_q, real_pool_am), [1]), tf.mul(len_pool_q, len_pool_am))
return q_ap_cosine, q_am_cosine
# 损失节点
def add_loss_op(self, q_ap_cosine, q_am_cosine):
# margin值,论文用的0.009
margin = tf.constant(self.config.m, shape=[self.config.batch_size], dtype=tf.float32)
# 0常量
zero = tf.constant(0., shape=[self.config.batch_size], dtype=tf.float32)
l = tf.maximum(zero, tf.add(tf.sub(margin, q_ap_cosine), q_am_cosine))
loss = tf.reduce_sum(l)
tf.add_to_collection('total_loss', loss)
total_loss = tf.add_n(tf.get_collection('total_loss'))
accu = tf.reduce_mean(tf.cast(tf.equal(zero, l), tf.float32))
# print 'q_am_cosine[shape]:', tf.shape(q_am_cosine)
# print 'q_ap_cosine[shape]:', tf.shape(q_ap_cosine)
# print 'loss[shape]:', tf.shape(loss)
# print 'accu[shape]:', tf.shape(accu)
return total_loss, loss, accu
# 训练节点
def add_train_op(self, loss):
with tf.name_scope('train_op'):
# 记录训练步骤
self.global_step = tf.Variable(0, name='global_step', trainable=False)
opt = tf.train.AdamOptimizer(self.config.lr)
train_op = opt.minimize(loss, self.global_step)
return train_op
训练 train.py
代码中的insurance_qa_data_helpers用于提取数据。
# -*- encoding:utf-8 -*-
from qacnn import QACNN
import tensorflow as tf
import numpy as np
import os
import time
import datetime
import operator
import insurance_qa_data_helpers
# Config函数
class Config(object):
def __init__(self, vocab_size):
# 输入序列(句子)长度
self.sequence_length = 200
# 循环数
self.num_epochs = 100000
# batch大小
self.batch_size = 100
# 词表大小
self.vocab_size = vocab_size
# 词向量大小
self.embedding_size = 100
# 不同类型的filter,相当于1-gram,2-gram,3-gram和5-gram
self.filter_sizes = [1, 2, 3, 5]
# 隐层大小
self.hidden_size = 80
# 每种filter的数量
self.num_filters = 512
# L2正则化,未用,没啥效果
# 论文里给的是0.0001
self.l2_reg_lambda = 0.
# 弃权,未用,没啥效果
self.keep_prob = 1.0
# 学习率
# 论文里给的是0.01
self.lr = 0.01
# margin
# 论文里给的是0.009
self.m = 0.05
# 设定GPU的性质,允许将不能在GPU上处理的部分放到CPU
# 设置log打印
self.cf = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
# 只占用20%的GPU内存
self.cf.gpu_options.per_process_gpu_memory_fraction = 0.2
print 'Loading Data...'
# 词映射ID
vocab = insurance_qa_data_helpers.build_vocab()
# 只记录train里的回答
alist = insurance_qa_data_helpers.read_alist()
# raw语料,记录所有train里的raw数据
raw = insurance_qa_data_helpers.read_raw()
testList, vectors = insurance_qa_data_helpers.load_test_and_vectors()
print 'Loading Data Done!'
# 测试目录
val_file = 'insuranceQA/test1'
# 配置文件
config = Config(len(vocab))
# 开始训练和测试
with tf.device('/gpu:0'):
with tf.Session(config=config.cf) as sess:
# 建立CNN网络
cnn = QACNN(config, sess)
# 训练函数
def train_step(x_batch_1, x_batch_2, x_batch_3):
feed_dict = {
cnn.q: x_batch_1,
cnn.aplus: x_batch_2,
cnn.aminus: x_batch_3,
cnn.keep_prob: config.keep_prob
}
_, step, loss, accuracy = sess.run(
[cnn.train_op, cnn.global_step, cnn.loss, cnn.accu],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print "{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy)
# 测试函数
def dev_step():
scoreList = list()
i = 0
while True:
x_test_1, x_test_2, x_test_3 = insurance_qa_data_helpers.load_data_val_6(testList, vocab, i, config.batch_size)
feed_dict = {
cnn.q: x_test_1,
cnn.aplus: x_test_2,
cnn.aminus: x_test_3,
cnn.keep_prob: 1.0
}
batch_scores = sess.run([cnn.q_ap_cosine], feed_dict)
for score in batch_scores[0]:
scoreList.append(score)
i += config.batch_size
if i >= len(testList):
break
sessdict = {}
index = 0
for line in open(val_file):
items = line.strip().split(' ')
qid = items[1].split(':')[1]
if not qid in sessdict:
sessdict[qid] = list()
sessdict[qid].append((scoreList[index], items[0]))
index += 1
if index >= len(testList):
break
lev1 = .0
lev0 = .0
for k, v in sessdict.items():
v.sort(key=operator.itemgetter(0), reverse=True)
score, flag = v[0]
if flag == '1':
lev1 += 1
if flag == '0':
lev0 += 1
# 回答的正确数和错误数
print '回答正确数 ' + str(lev1)
print '回答错误数 ' + str(lev0)
print '准确率 ' + str(float(lev1)/(lev1+lev0))
# 每5000步测试一下
evaluate_every = 5000
# 开始训练和测试
sess.run(tf.initialize_all_variables())
for i in range(config.num_epochs):
# 18540个训练样本
# 20000+个预训练词向量,此处没有用,不过可以加进去
x_batch_1, x_batch_2, x_batch_3 = insurance_qa_data_helpers.load_data_6(vocab, alist, raw, config.batch_size)
train_step(x_batch_1, x_batch_2, x_batch_3)
if (i+1) % evaluate_every == 0:
# 共20个问题,每个问题500个,对应1到2个正确答案,499到498个错误答案
# 相当于从一个size=500的pool里选出正确答案
print "\n测试{}:".format((i+1)/evaluate_every)
dev_step()
print
实验结果
此次实验迭代次数设置的比较小,大概需要8到9个小时。从损失函数上看,随着迭代的增加,损失逐渐收敛。而在测试的时候,由于只有20个例子,因此测试波动比较大。可以通过增大batch_size、迭代次数以及训练样本和测试样本的大小让结果更稳定,效果更好。
此次实验结果如下:
测试1:
回答正确数 5.0
回答错误数 15.0
准确率 0.25
测试2:
回答正确数 4.0
回答错误数 16.0
准确率 0.2
测试3:
回答正确数 6.0
回答错误数 14.0
准确率 0.3
测试4:
回答正确数 5.0
回答错误数 15.0
准确率 0.25
测试5:
回答正确数 5.0
回答错误数 15.0
准确率 0.25
测试6:
回答正确数 4.0
回答错误数 16.0
准确率 0.2
测试7:
回答正确数 5.0
回答错误数 15.0
准确率 0.25
测试8:
回答正确数 3.0
回答错误数 17.0
准确率 0.15
测试9:
回答正确数 4.0
回答错误数 16.0
准确率 0.2
测试10:
回答正确数 5.0
回答错误数 15.0
准确率 0.25
测试11:
回答正确数 6.0
回答错误数 14.0
准确率 0.3
测试12:
回答正确数 3.0
回答错误数 17.0
准确率 0.15
测试13:
回答正确数 6.0
回答错误数 14.0
准确率 0.3
测试14:
回答正确数 5.0
回答错误数 15.0
准确率 0.25
测试15:
回答正确数 4.0
回答错误数 16.0
准确率 0.2
测试16:
回答正确数 4.0
回答错误数 16.0
准确率 0.2
测试17:
回答正确数 4.0
回答错误数 16.0
准确率 0.2
测试18:
回答正确数 5.0
回答错误数 15.0
准确率 0.25
测试19:
回答正确数 6.0
回答错误数 14.0
准确率 0.3
测试20:
回答正确数 8.0
回答错误数 12.0
准确率 0.4