Previous
自然语言处理——语言模型
自然语言处理——词法分析与词性标注
自然语言处理——语法分析
自然语言处理——句法分析
自然语言处理——浅层句法分析和依存句法分析
浅层句法分析
- 概念:识别句子中的一些相对简单的独立成分(语块)
- 任务:(1)语块的识别与分析;(2)语块之间的依存关系
- 语块的概念:包含位词、非递归短语、子句
- 名词短语句法分析:利用IOB来标记语块,或者块标注法标记语块,并且可以使用下面的方法来训练模型(1)使用SVM;(2)使用WINNOW;(3)使用CRF
依存句法分析
思路
句法关联建立起词和词之间的关联,包括支配词和从属词。依存语法是指支配与被支配的关系。(依存语法认为动词是句子的中心,其他词都是由动词所支配。)
优点
- 简单,直接考虑词之间的关联;
- 不过多强调句子中的固定词序;
- 受深层语义结构驱动,依存本质是语义上的;
- 形式化程度较短语结构更浅。
依存句法分析方法
包括判别式、生成式、确定性依存分析、基于约束满足的分析方法(规则方法)。
- 生成式:考虑联合分布最大时的依存语法树(需要以词和词之间是独立的作为前提条件)
- 判别式:考虑条件概率最大(可以不考虑词和词之间的独立性)
- 模仿人的认知过程,按照特定方向每次读入一个词。每读入一个词,就进行一次决策。
- 优点:速度快
- 缺点:不可回溯(局部最优)
- 举例:Arc-eager算法(包含四种分析动作:Left-Arc、Right-Arc、Reduce、Shift),算法例子放在后面
评价指标
- 无标记依存正确率:测试集中找到其正确支配词的词所占总次数的百分比;
- 带标记依存正确率:测试集中找到其正确支配词的词,并且依存关系类型也标注正确的词占总词数的百分比;
- 依存正确率:测试集中找到正确支配词非根结点词占所有非根结点词总数的百分比;
- 根正确率:测试集中正确根结点的个数与句子个数的百分比;或者是指测试集中找到正确根结点的句子数占总句子数百分比;
- 完全匹配率:测试集中无标记依存结构完全正确的句子占句子总数的百分比。
依存分析树与短语结构树的关系
依存分析树可以由短语结构树得到,但是反过来不行(一颗依存分析树对应多种可能的短语结构树)。
转换步骤:
- 定义中心词抽取规则,产生中心词表;
- 根据中心词表,为句法树中每个节点选择中心子结点;
- 同一层的非中心子结点中心词依存到中心子结点的中心词上,下一层的中心词依存到上一层的中心词上。
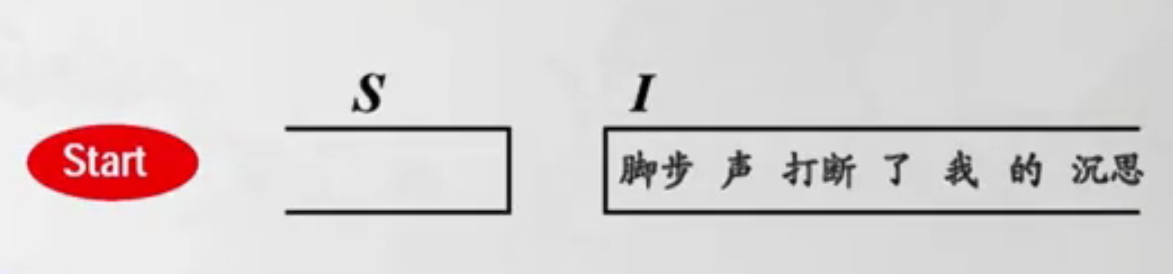
Arc-eager算法举例
由于截图不是特别清楚,我们再用文字描述一遍。
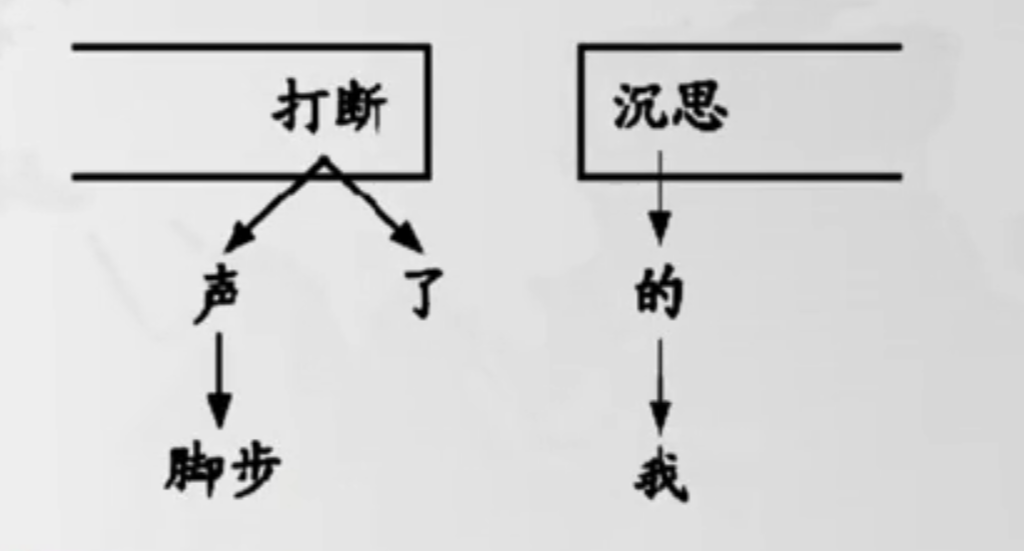
左边的S表示栈,右边为待处理的已分词的句子。句子内容为“脚步声打断了我的沉思”。具体步骤描述如下:
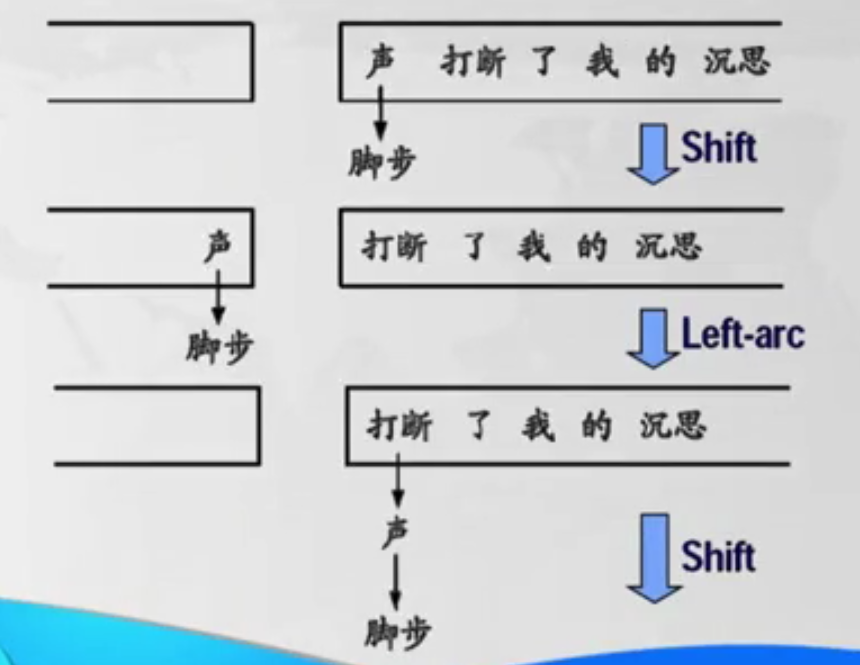
- Left-Arc:将“脚步”存入栈中,之后取栈顶元素(“脚步”)和队头元素(“声”)比较,如果两者有依存关系,且“声”支配“脚步”,则进行Left-Arc操作;
- Shift:将已经完成的部分放入栈中(如下图);
- Left-Arc:比对当前栈顶元素(“声”)和队列元素(“打断”)的依存关系,发现也是Left-Arc,那么进行Left-Arc操作;
- Shift;
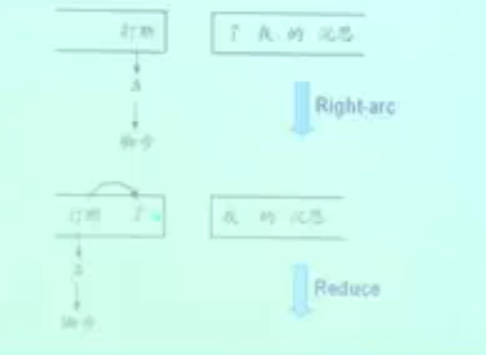
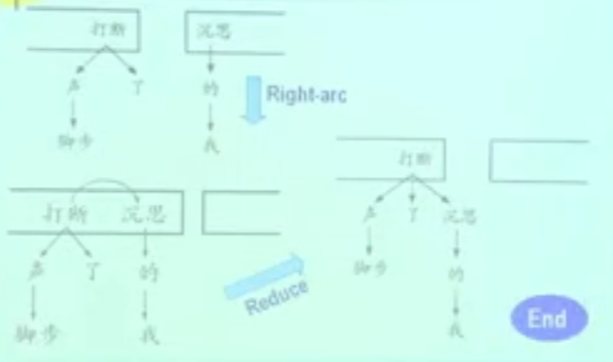
- Right-Arc:“打断”支配“了”,为Right-Arc;
- Reduce:由于栈顶元素不是根结点,所以要进行规约,使得“打断”在栈顶;
- Shift:由于“我”和“打断”没有依存关系,所以将“我”移入栈顶;
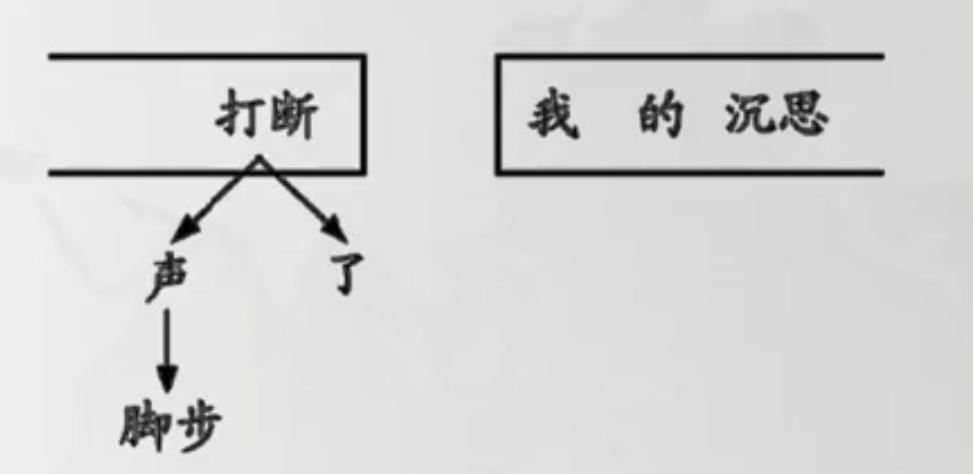
- Left-Arc:“的”支配“我”;
- Shift;
- Left-Arc:“沉思”支配“的”;
- Right-Arc:“打断”支配“沉思”;
- Reduce:让“打断”在栈顶;
- End。