Previous
1.Tensorflow学习笔记(一) 基础
2.Tensorflow学习笔记(二) Toy Demo
Tensorflow学习笔记(三) 使用Skip-Gram和CBOW训练Word Embedding
这部分使用了比较简单的思路实现了word2vec。原来的部分只有SG,后面我自己加了CBOW的方法。其实SG和CBOW很相似,只是在取数据的时候有些差异,其余的都是一样的。
- 如果没有搞懂这两个的原理以及如何实现,可以看看CS224d里的前几节。
- 如果很清楚这两个的原理,并且自己也不用Tensorflow动手实现过这两个算法,下面的代码会很简单。可以直接看官方教程或者word2vec实现源码。
- 如果只是比较清楚原理,下面的代码配上注释仔细看应该也比较容易看懂。
# -*- encoding:utf-8 -*-
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import math
import os
import random
import zipfile
import numpy as np
import urllib
import tensorflow as tf
## ----------------1.下载数据----------------
# 下载训练数据的网址
url = 'http://mattmahoney.net/dc/'
# 下载
def download(filename, expected_bytes):
# 判断是否已经下了文件,没有则下
if not os.path.exists(filename):
filename, _ = urllib.request.urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
# 判定字节状态是否正确,正确表示下载对了
if statinfo.st_size == expected_bytes:
print('Found and verified', filename)
else:
print(statinfo.st_size)
raise Exception(
'Failed to verify ' + filename + '. Can you get to it with a browser?')
return filename
filename = download('text8.zip', 31344016)
## ----------------2.读取数据----------------
def read_data(filename):
# 解压
with zipfile.ZipFile(filename) as f:
# 读取第一个文件
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
# 格式为list,是一列词组成的文本序列
words = read_data(filename)
print('Data size', len(words))
print(type(words))
# 设置字典大小为50000
vocabulary_size = 50000
def build_dataset(words):
# 未知词
count = [['UNK', -1]]
# 统计words里的各个词出现的词频,选取前49999个高频词,其余都属于'UNK'
count.extend(collections.Counter(words).most_common(vocabulary_size-1))
# d是词映射id
d = dict()
for word, _ in count:
d[word] = len(d)
# data即words的id版本
data = list()
unk_count = 0
for word in words:
if word in d:
index = d[word]
else:
index = 0
unk_count += 1
data.append(index)
# 设置未知词数量
count[0][1] = unk_count
# 反过来的词典,从id映射到词
reverse_d = dict(zip(d.values(), d.keys()))
return data, count, d, reverse_d
# data:词id序列
# count:前50000个高频词
# d:词序列映射到id
# reverse_d:id映射到词序列
data, count, d, reverse_d = build_dataset(words)
# 删除以减小内存
del words
print('Most common words (+UNK)', count[:5])
print('Sample data', data[:10], [reverse_d[i] for i in data[:10]])
## ----------------3.生成用于训练的数据(分别给出SG和CBOW)----------------
# 全局的data的索引变量
data_index = 0
# Skip-Gram
# batch_size:批量训练时的数据量大小
# num_skips:表示一个输入中心词对应的输出词.比如词窗为2,总长为5,则num_skips=4
# skip_window:表示目标词左右的词窗大小,比如2是中心词,词窗大小为1,则窗口为[5,2,8],其中5和8为2的邻近词
def generate_batch_sg(batch_size, num_skips, skip_window):
global data_index
# assert batch_size%num_skips == 0
# assert num_skips <= 2*skip_window
# 批量数据的样本值,存中心词的id,即输入
batch = np.ndarray(shape=[batch_size], dtype=np.int32)
# 批量数据的标签,存中心词的邻近词id,即输出
labels = np.ndarray(shape=[batch_size, 1], dtype=np.int32)
# 窗口大小
span = 2*skip_window+1
# 双端队列,保持长度为span
dq = collections.deque(maxlen=span)
# 初始化dq
for _ in range(span):
dq.append(data[data_index])
data_index = (data_index+1)%len(data)
# 开始产生batch和labels
for i in range(batch_size//num_skips):
target = skip_window
visited = [skip_window]
for j in range(num_skips):
while target in visited:
target = random.randint(0, span-1)
visited.append(target)
batch[i*num_skips + j] = dq[skip_window]
labels[i*num_skips + j, 0] = dq[target]
dq.append(data[data_index])
data_index = (data_index+1)%len(data)
return batch, labels
# CBOW
# batch_size:批量训练时的数据量大小
# num_skips:表示一个输入中心词对应的输出词.比如词窗为2,总长为5,则num_skips=4
# skip_window:表示目标词左右的词窗大小,比如2是中心词,词窗大小为1,则窗口为[5,2,8],其中5和8为2的邻近词
def generate_batch_cbow(batch_size, num_skips, skip_window):
global data_index
# assert batch_size%num_skips == 0
# assert num_skips <= 2*skip_window
# 批量数据的样本值,存中心词的id,即输入
batch = np.ndarray(shape=[batch_size], dtype=np.int32)
# 批量数据的标签,存中心词的邻近词id,即输出
labels = np.ndarray(shape=[batch_size, 1], dtype=np.int32)
# 窗口大小
span = 2*skip_window+1
# 双端队列,保持长度为span
dq = collections.deque(maxlen=span)
# 初始化dq
for _ in range(span):
dq.append(data[data_index])
data_index = (data_index+1)%len(data)
# 开始产生batch和labels
for i in range(batch_size//num_skips):
target = skip_window
visited = [skip_window]
for j in range(num_skips):
while target in visited:
target = random.randint(0, span-1)
visited.append(target)
# 就这里CBOW和SG不同
batch[i*num_skips + j] = dq[target]
labels[i*num_skips + j, 0] = dq[skip_window]
dq.append(data[data_index])
data_index = (data_index+1)%len(data)
return batch, labels
batch, labels = generate_batch_sg(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):
print(batch[i], reverse_d[batch[i]],
'->', labels[i, 0], reverse_d[labels[i, 0]])
## ----------------4.绘制计算图----------------
# 批量数据大小
batch_size = 128
# 词向量维度
embedding_size = 128
skip_window = 1 # How many words to consider left and right.
num_skips = 2 # How many times to reuse an input to generate a label.
# 验证集大小
valid_size = 16
# 总的验证集窗口,即前100个
valid_window = 100
# 从总的100个验证集中选出16个
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
# 负样本数量
num_sampled = 64
# 图
graph = tf.Graph()
with graph.as_default():
# 训练输入和标签
train_inputs = tf.placeholder(tf.int32, [batch_size])
train_labels = tf.placeholder(tf.int32, [batch_size, 1])
# 验证集
valid_dataset = tf.constant(valid_examples, tf.int32)
# 选定CPU
with tf.device('/cpu:0'):
with tf.variable_scope('Embedding'):
# 要训练的词向量
embeddings = tf.get_variable('embed', shape=[vocabulary_size, embedding_size],
initializer=tf.random_uniform_initializer(-1., 1.))
# 目前训练的词
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# NCE即Noise-contrastive estimation
# 设置NCE需要的weights和biases
nce_weights = tf.get_variable('nce_w', shape=[vocabulary_size, embedding_size],
initializer=tf.random_normal_initializer(.0, math.sqrt(6./(vocabulary_size+embedding_size))))
nce_biases = tf.get_variable('nce_b', shape=[vocabulary_size],
initializer=tf.constant_initializer(.0))
# nce损失
loss = tf.reduce_mean(
tf.nn.nce_loss(nce_weights, nce_biases, embed, train_labels, \
num_sampled, vocabulary_size))
# 优化器
opt = tf.train.AdamOptimizer(1.).minimize(loss)
# 归一化词向量,并进行验证集验证
norm = tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
## ----------------5.开始训练词向量----------------
# 训练步骤数
num_steps = 100001
# 创建会话
with tf.Session(graph=graph) as sess:
# 初始化所有变量
sess.run(tf.initialize_all_variables())
# 平均损失
average_loss = 0.
print('Start training')
for step in range(num_steps):
# 获取批量数据
batch_inputs, batch_labels = generate_batch_sg(batch_size, num_skips, skip_window)
feed_dict = {train_inputs:batch_inputs, train_labels:batch_labels}
# 开始迭代训练
_, loss_val = sess.run([opt, loss], feed_dict=feed_dict)
average_loss += loss_val
# 每训练2000步,输出这2000步的平均损失
if step%2000 == 0:
if step>0:
average_loss = average_loss/2000.
print('step:%d, loss:%f' % (step, average_loss))
average_loss = 0.
# 每训练50000步,用验证集验证每个验证词与词典里其他词的词向量相似度
# 这个会大大降低训练速度,不建议在训练的时候加进来
if step%50000 == 0:
sim = similarity.eval()
for i in xrange(valid_size):
cur_word = reverse_d[valid_examples[i]]
top_k = 10
nearest = (-sim[i,:]).argsort()[1:top_k+1]
print('Nearest word:%s' % cur_word)
log_str = ""
for z in xrange(top_k):
close_word = reverse_d[nearest[z]]
log_str = '%s %s' % (log_str, close_word)
print(log_str)
final_embeddings = normalized_embeddings.eval()
## ----------------6.绘制词向量图----------------
def plot_with_labels(low_dim_embs, labels, filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings"
plt.figure(figsize=(18, 18)) #in inches
for i, label in enumerate(labels):
x, y = low_dim_embs[i,:]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename)
## ----------------7.整体的运行----------------
try:
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
# 不太清楚,没有查.应该是用PCA将词向量降维到2维.其实也可以使用矩阵分解取前两维语义信息
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
# 只画前500个词向量
plot_only = 500
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only,:])
labels = [reverse_d[i] for i in xrange(plot_only)]
# 画图
plot_with_labels(low_dim_embs, labels)
except ImportError:
print("Please install sklearn, matplotlib, and scipy to visualize embeddings.")
结果
使用Skip-Gram:
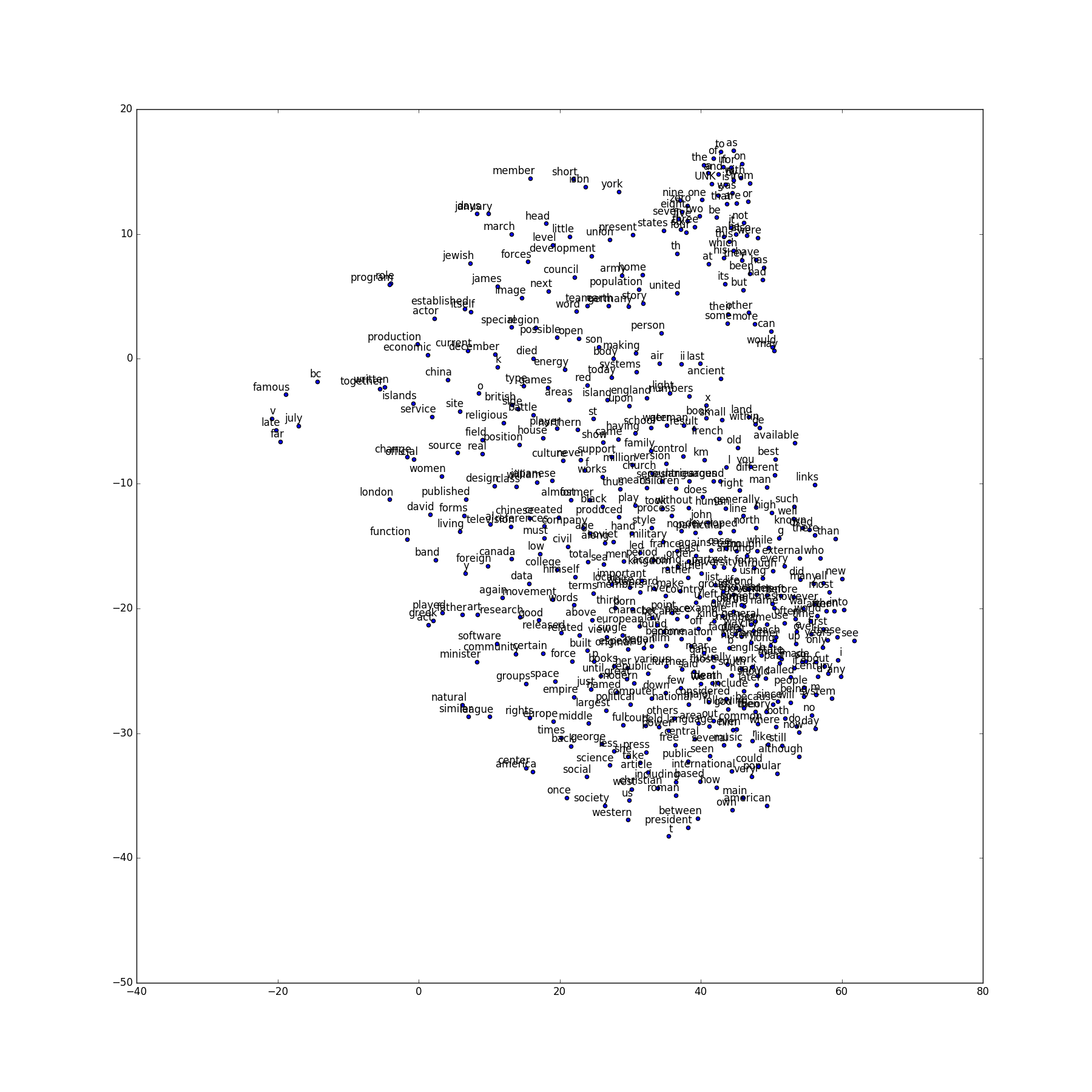
使用CBOW:
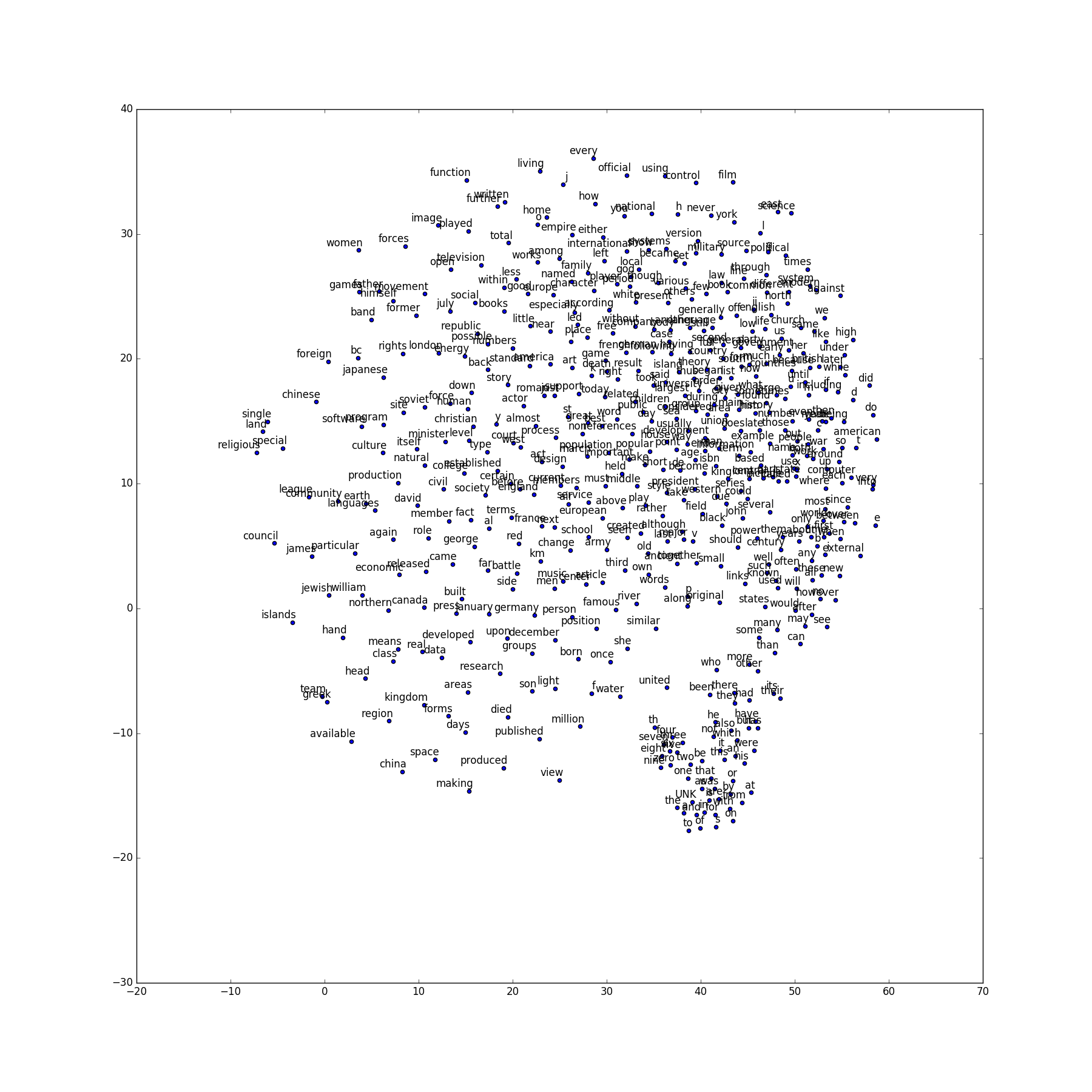
可以看到,语义或语法相似的词汇聚集到一起。
现在效果比较好的word embedding是用glove来训练词向量,它在语义和语法表征上都比较好。它的基本原理是在考虑词的局部词窗外考虑全局的词的共现频率。
参考
1.Vector Representations of Words