Seq2Seq与Attention机制
Seq2Seq
Seq2Seq即Sequence to Sequence,是一种时序对映射的过程,实现了深度学习模型在序列问题中的应用,其中比较突出的是机器翻译和机器人问答。Seq2Seq的思想最早由两篇论文引出,分别为《Sequence to Sequence Learning with Neural Networks》和《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。
Seq2Seq主要由两个RNN模型组成,一个用于encode输入序列(将词序列转变为一个固定大小的向量),一个是将encode的结果decode(将获得的语义向量转为一个token序列,即词序列),故称为RNN Encoder-Decoder。
Seq2Seq的大致过程如下图,前3个为encoder层,后5个是decoder层。
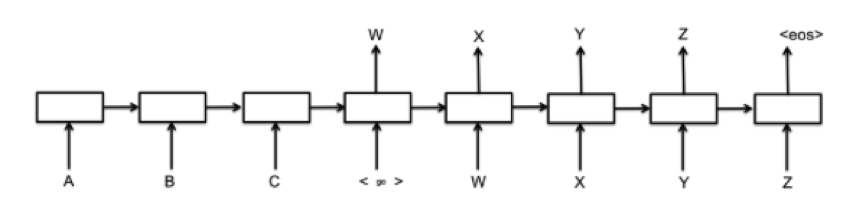
encode
RNN依次读入token(词向量),之后在Encoder最后一个隐藏层输出一个固定长度的vector,设为c,它是整个序列的概括,包含从x1到xn的token序列的信息。

decode
按照下式求出优化目标,之后求极大似然估计即可。
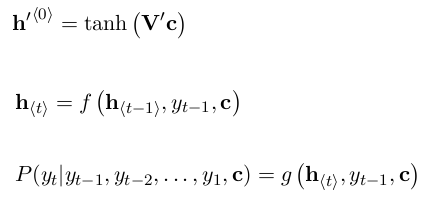
Attention
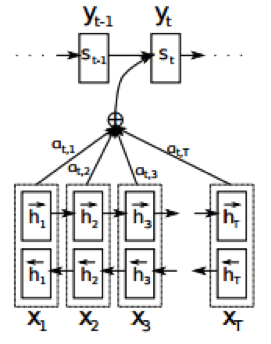
作为Seq2Seq中的重要组成部分,注意机制最早由Bahdanau等人于2014年提出,该机制存在的目的是为了解决RNN中只支持固定长度输入的瓶颈。在该机制环境下,Seq2Seq中的编码器被替换为一个双向循环网络(bidirectional RNN)。原来的Encode部分被替换为了BRNN,这使得对于每个输出y,都和之前的输出以及当前的整个句子有关。有了Attention机制,我们不再需要将完整的原文句子编码为固定长度的向量。相反,我们允许解码器在每一步输出时“参与(attend)”到原文的不同部分。尤为重要的是我们让模型根据输入的句子以及已经产生的内容来决定参与什么。因此,在形式非常相似的语种之间(如英语与德语),解码器可能会选择顺序地参与事情。生成第一个英语词语时参与原文的第一个词语,以此类推。如上图所示,在注意机制中,我们的源序列x=(x1,x2,…,xt)分别被正向与反向地输入了模型中,进而得到了正反两层隐节点,语境向量c则由RNN中的隐节点h通过不同的权重a加权而成,其公式如下:
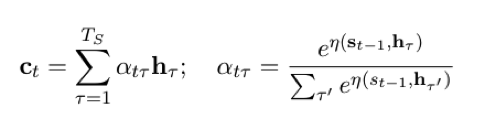
参考
[1] Seq2Seq的DIY简介
[2] seq2seq模型
[3] 深度学习和自然语言处理中的attention和memory机制