layout: post title: 使用Python2实现简单的搜索引擎 date: 2016-11-07 categories: blog tags: [搜索引擎] description: 使用简单的VSM模型和TF-IDF来建立搜索引擎 —
使用Python2实现简单的搜索引擎
一、 开发流程
1. 爬虫与信息抽取
1.1 实现功能与方法
此模块实现了两种方式:
- 全部使用正则表达式匹配;
- 使用Scrapy建立Crawler工程通过tag来匹配抓取。第一种方式先下载网页,然后使用正则表达式来匹配网页,提取信息,存储到本地磁盘;第二种方式在爬取网页的时候直接提取我们需要的信息,并保存到数据库。
具体实现:
第一种方法:
通过Python来对特定网站(此处我们针对豆瓣电影信息进行收集,并建立电影导向的信息检索系统)进行数据抓取,保证友好访问(平均1秒访问一个网页),采用广度优先遍历(BFS),尽可能使得各种类型的影片数量均衡。目前收集的电影数量(网页数量)有1000、2000和5000三种。我们采用2000数量级的数据。
第二种方法:
(1)设定起始网页,从这个页面开始,对该页面内的所有有效链接进行BFS,然后对有效链接进行请求,获取html文本,并从中按照tag标记来获取想要的数据,并保存到数据库里(此处我们使用的是mysql);
(2)之后需要使用数据建立索引、搜索、做数据结构化的时候,可以直接通过python访问mysql的api接口。
1.2 问题与解决方案
(1)个别电影网页的标签和匹配项不太一样,容易造成混淆;
解决方法:对数据进一步清洗。
(2)需要从网页中提取的有用的文本信息里会有包含噪声数据(比如html的换行
),需要对这些数据做特殊处理。
解决方法:使用文本替换的方法,把
标签替换为空格,把多个连续的空格压缩为一个空格。
(3)由于Scrapy是用于大量网页的爬取,没有直接的中断机制,需要采集到一定数量后人为切断程序。
解决方法:可以使用脚本,当程序运行到一定阶段后(通过输出到stdout上的信息来判定),自动杀死进程。
2. 建立索引
2.1 实现功能与方法
由于电影、导演、编剧以及演员的名字具有独立性和完整性,通过切词容易造成误判,所以将这部分的内容直接加入到切词列表中,保证能够被完整识别出来。比如《格莫拉 第一季》,需要将”格莫拉“作为一个全词。再考虑名称的分隔符,比如“ ”、“:”等,都是常见的分隔符,需要以此为间隔将完整的名称分割开,以提升搜索的准确性(因为很少有人会输入完整的名)。
具体细节:
(1)将所有专有名词加入到切词字典中,保证存在完整切割的词。对每个文档(网页),均进行分词,建立词集项,并对每个词统计词频;
(2)建立倒排索引,通过词映射文档编号,每个文档编号映射对应的文档内容;
(3)使用建立的倒排索引,计算每个词在每个文档里的tf-idf值,确定这个词在所有文档里的tf-idf最大值;
(4)对每个词的最大tf-idf进行阈值过滤,选择tf-idf大于(或等于)阈值的词,作为关键词keyword;
(5)通过倒排索引建立term-doc矩阵,每一行表示一个关键词在各个文档里的词频,每一列代表一个文档里的各个关键词词频;
(6)使用LSI进行词向量压缩,对建立的矩阵进行奇异值分解(SVD),压缩特征矩阵,获得语义压缩矩阵。由于这一步在单机上耗时太长,故实验时省略。大家可以尝试一下。
2.2 问题与解决方案
(1)一开始使用5000份网页作为基础数据库建立索引,由于电影信息的特殊性(由于人名、电影名称等都需要作为关键词出现,这导致关键词数量需要很大才能够保证检索的召回率高),使得最后算出的term-doc矩阵较大(1000005000),不论是在内存里直接计算得出还是先存储到本地再进行读取矩阵(直接用json或pickle存储的话,大小能达到2.3G)个人电脑都难以在短时间内处理,因此考虑使用2000份网页作为基础建立索引(矩阵大小大概为560002000),或者增大阈值来减少关键词数量;
(2)无论是1000份网页的数据还是2000份网页的数据还是5000份网页的数据,奇异值分解(SVD)在分解大矩阵的时候需要非常长的时间,使得个人电脑无法高效完成,只能在小文档范围内进行测试。
3. 信息检索
3.1 实现功能与方法
信息检索的功能是让用户输入查询语句,之后反馈给用户相关的文档信息。
具体细节:
(1)将提交的query建立VSM模型,并将query向量和最终的term-doc作乘法;
(2)将最终值进行文档排序,过滤掉不相关(乘积为0)或者负相关(乘积小于0)的文档,输出正相关文档的详细信息。
3.2 问题与解决方案
(1)有时候输入的query只能匹配query切词后的部分内容,而无法匹配整个query(前提是这个query作为一个整体在倒排索引中存在),或者匹配的结果排名不高(这个和实际情况不符,比如我们搜索“惊天魔盗团”,匹配出的“惊天大逆转”排名会比惊天魔盗团高)。
解决方法:将整个query作为query的一个特征,并提升这个特征的权重(比如在基础权重上乘以一个常数)。
4. 额外扩展
4.1 PageRank实现网页初始排名
使用经典的PageRank算法对网页进行初始排名,使用公式:
\(V^{'}={\alpha}MV+(1-\alpha)e\) 计算网页的各个得分,然后进行排序。这个公式可以解决网页陷阱问题(某个网页有且只有指向自身的链接)和网页终止点问题(网页不指向任何链接),防止出现最终结果稳定收敛到某个网页(该网页的得分为1)或者所有网页的得分收敛到0。
具体细节:
可以将PageRank获得的网页得分与query相关度得到的网页得分进行整合,分别对两者进行归一化,然后直接将两者的分数相加,用来表示最后的得分。
4.2 query的扩展
使用HIT的同义词词林来扩展已被切词的query,扩大搜索范围。
4.3 UI界面
使用PyQt来实现搜索引擎界面,包括搜索输入栏、搜索按钮以及结果浏览框。运行UI时需要一段时间将整个电影库加载到内存中运行,之后便可以在搜索框对想要的结果进行搜索。由于是单机操作,此处使用2000个网址运行。
二、 结果
1. 工程结构

- code:
- IRIE.py:实现整个信息检索功能,若不想运行UI界面,请运行该文件;
- douban_movie:使用Scrapy方法进行爬虫的工程目录;
- window.py:UI界面;
- data:
- html:包含html源文件(压缩包里不包括这个);
- info:包含从html里抽取的信息(压缩包里只包括2000数量级的);
- index:未用到;
- mul_pagerank.json:用来加载2000数量级文档的pagerank文件(各个网页之间的关联映射);
- dict:
- extendwords:同义词词林;
- stopwords:停用词(功能词)词典。
2. 爬虫结果
2.1 保存在本地磁盘的文件
html_2000文件夹下:
info_2000文件夹下:
info文件:

json格式保存,unicode编码格式,上图可以看到一部电影所抽取到的信息:电影名称name、地址url、编剧writer、导演director、演员actor和电影简介summary。
2.2 数据库里存储的结构化数据
表结构:
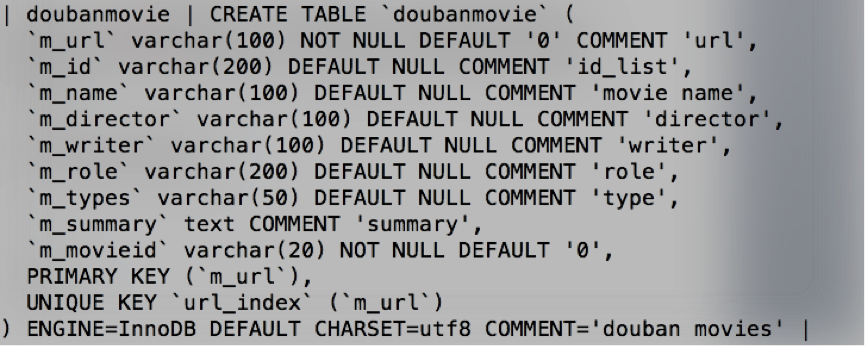
数据内容:

上述各个字段分别为:url地址、当前页面可以跳转的电影ID(用于PageRank)、电影名称、导演、编剧、演员、类型、电影简介、当前电影的ID。
3.索引

倒排文件的结构如上,每个词映射为一个哈希表,分别对应出现该词的电影ID和出现词频数。比如“俗话”这个词,在ID为“26430092”的电影里出现1次,在ID为“19961119”的电影里也同样出现1次。
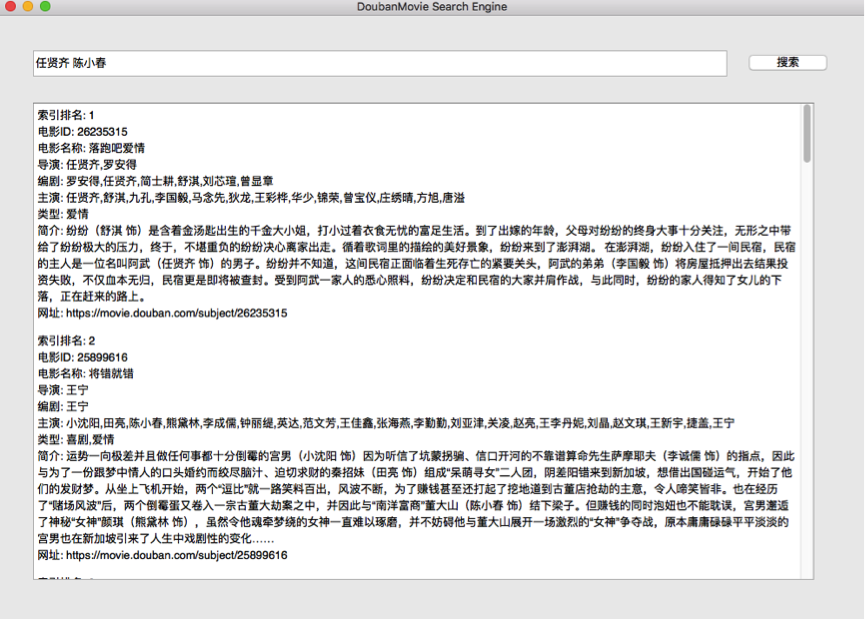
4.检索与UI界面展示

多元搜索:

5.PageRank收敛验证
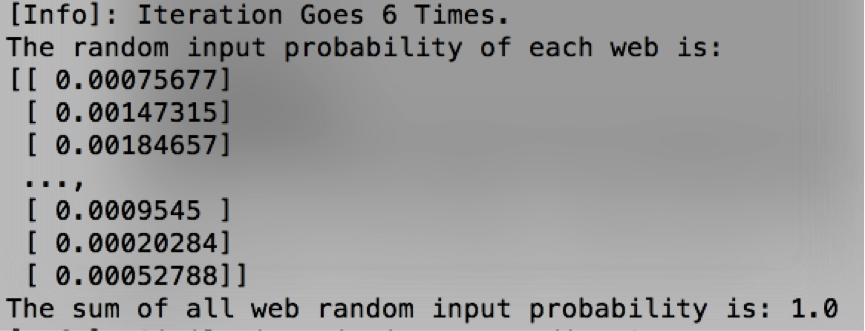 上述信息表明,PageRank迭代次数为6次。向量的每一维表示跳转到该部电影所在网站的概率,可以看到,跳转到各个电影网站的概率和为1,表明已收敛。
上述信息表明,PageRank迭代次数为6次。向量的每一维表示跳转到该部电影所在网站的概率,可以看到,跳转到各个电影网站的概率和为1,表明已收敛。